headscale 系列:组建 headscale 集群,把设备接入能力做成“无限接近无限”
· 阅读需 3 分钟
这篇文章分享 headscale 从单体到可线性扩展集群的核心改造路径:cluster_id 分片、共享 PostgreSQL、接入控制程序(ACS)、查询隔离与 netmap 增量化。
原文链接: headscale 系列:组建 headscale 集群,把设备接入能力做成“无限接近无限”
核心结论
通过以下组合,可以把 headscale 逐步改造成接近 SaaS 形态的控制面:
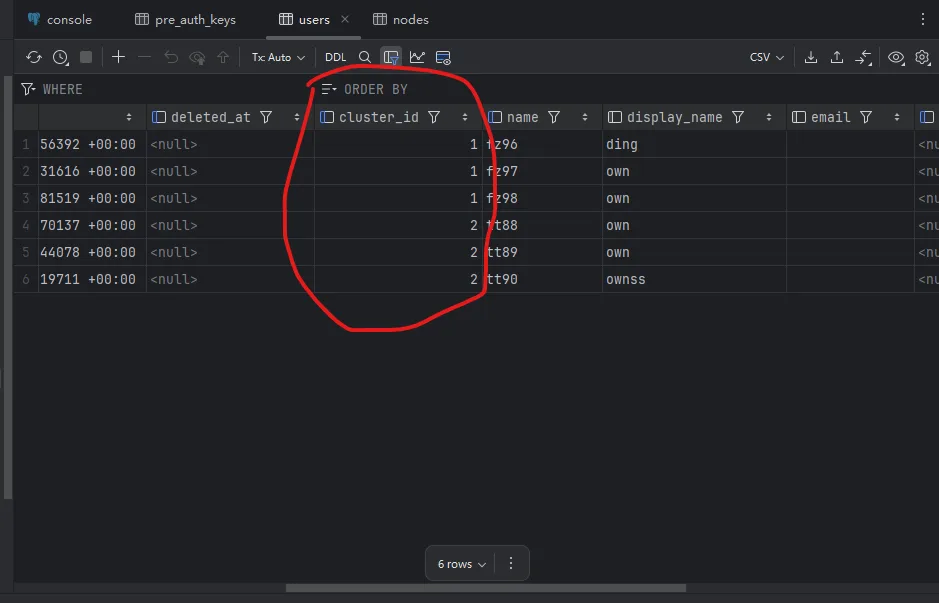
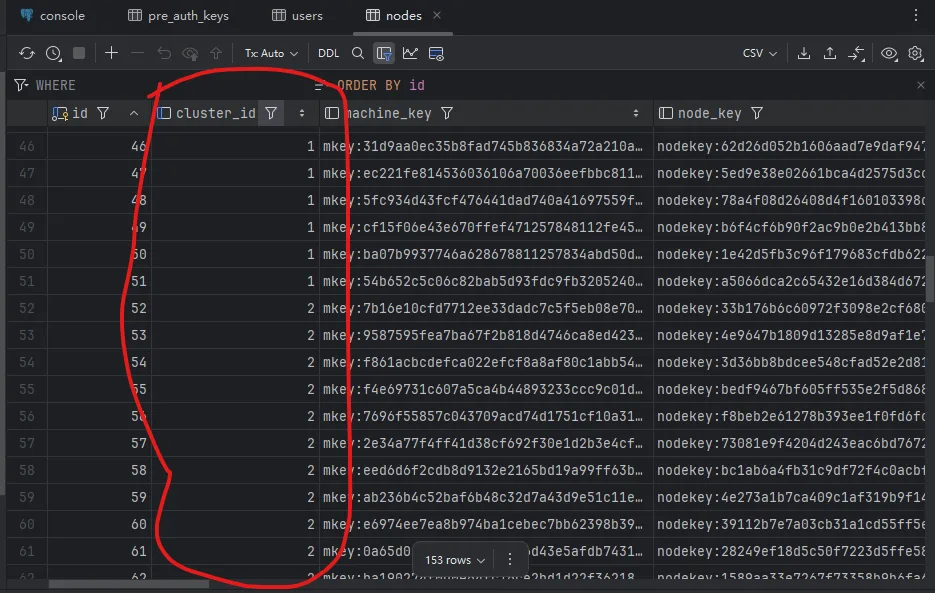
cluster_id逻辑分片- 共享 PG/PG 集群
- 接入控制程序(ACS)做分配与黏住
- DAO/ORM 层强制查询隔离
- netmap 计算从全量转为增量
架构要点
- 多个
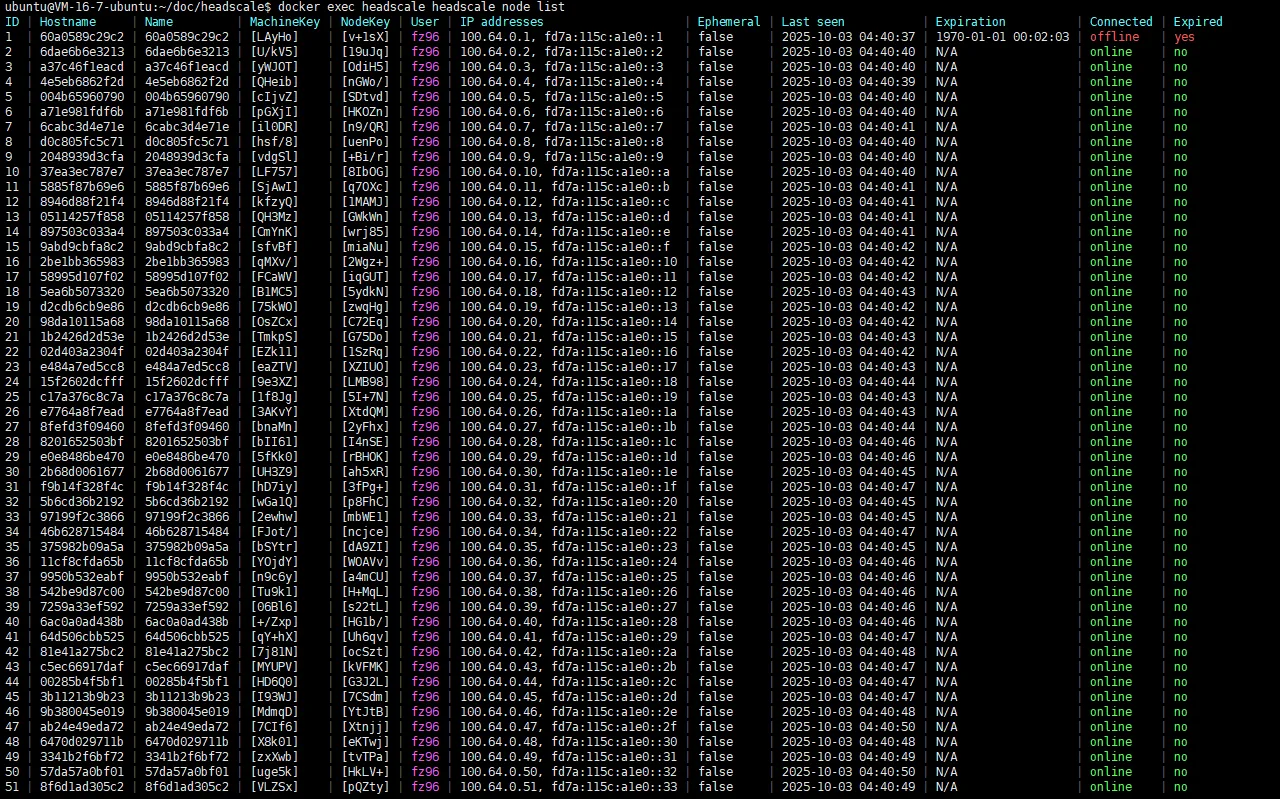
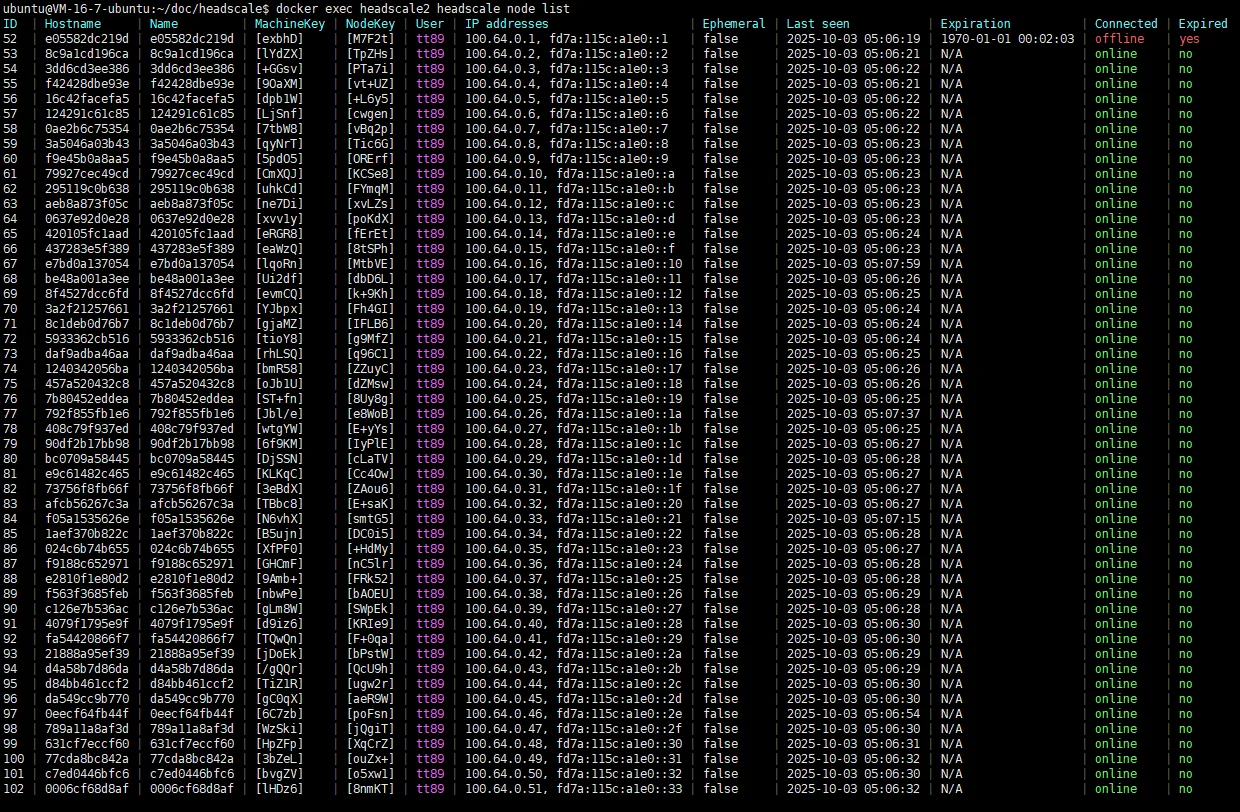
headscale节点并行运行,每个节点绑定独立cluster_id。 - 所有节点共享数据库,但查询必须显式包含
cluster_id。 - ACS 负责首次接入分配、配额策略、区域与负载选择、租户黏住。
- 配合 LISTEN/NOTIFY + 去抖合并,让 netmap 重建聚焦到受影响范围。
启动示例
CLUSTER_ID=A \
PG_DSN="postgres://..." \
DERP_MAP_URL="https://derp.example.com/map.json" \
./headscale --config ./config.yaml
数据与查询隔离示例
ALTER TABLE nodes ADD COLUMN cluster_id TEXT NOT NULL DEFAULT 'default';
CREATE INDEX idx_nodes_cluster_id ON nodes(cluster_id);
func (c *ClusterDB) Scoped() *gorm.DB {
return c.db.Where("cluster_id = ?", c.clusterID)
}
netmap 增量化思路
- 变更写入后触发
NOTIFY netmap_dirty(cluster_id, scope_key)。 - 节点只消费本
cluster_id事件。 - 按
scope_key(用户、tag、路由域)做增量重建与推送。 - 引入缓存与版本号,避免重复全量构建。
演示截图
相关链接
- 项目地址: OwnDing/headscale-saas
本文已同步到 Larktun 博客,原始内容与更新请以原文为准: headscale 系列:组建 headscale 集群,把设备接入能力做成“无限接近无限”