headscale 系列:Headscale SaaS 环境下的用户无缝切换实战
· 阅读需 3 分钟
当 Headscale SaaS 需要扩容、维护或做负载再平衡时,核心问题是如何让用户在迁移时尽量“无感”。本文给出一套实战方案:动态路由 + 系统层精准断链 + 自动重连。
原文链接: headscale-系列:Headscale-SaaS-环境下的用户无缝切换实战
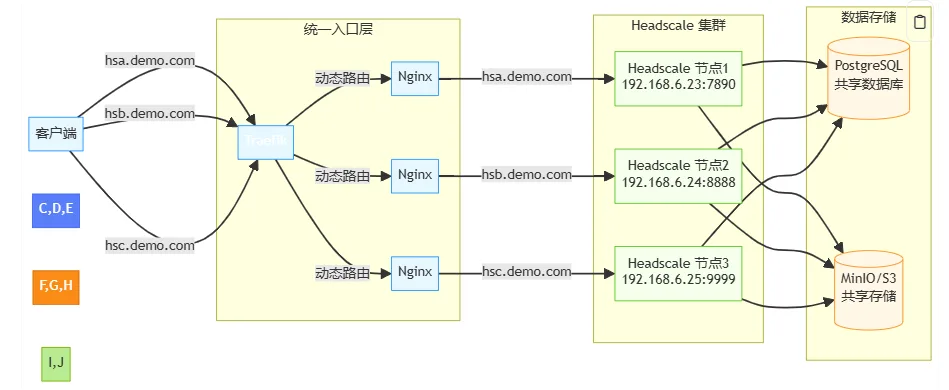
架构回顾
- 用户域名(如
hsa.demo.com)统一解析到 Traefik。 - Traefik 按域名把流量转发到对应 headscale 节点。
- 后端通过
cluster_id维度做数据隔离与迁移。
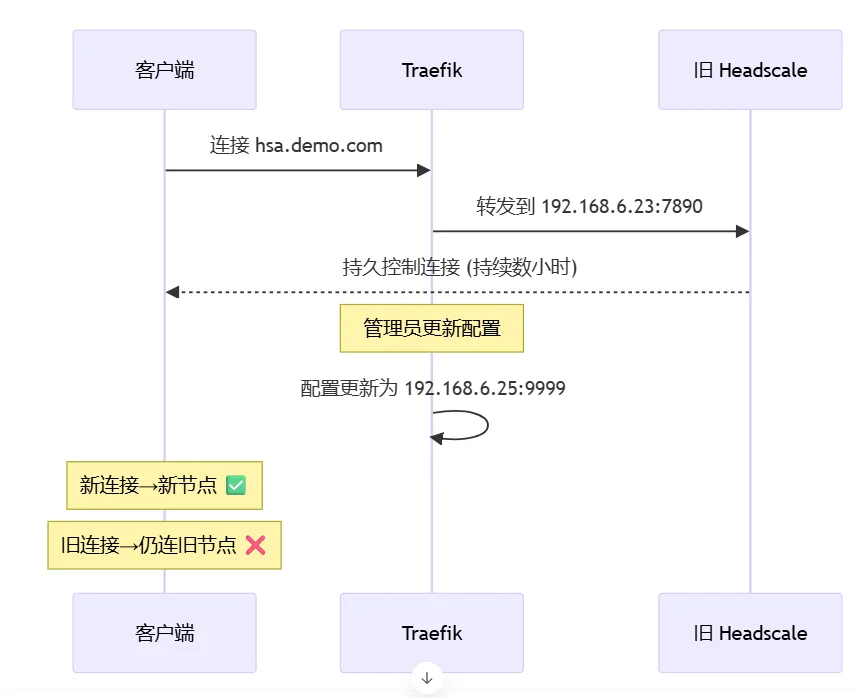
迁移难点
即使热更新反向代理路由,已经建立的 TCP 长连接通常不会立刻切换到新后端。
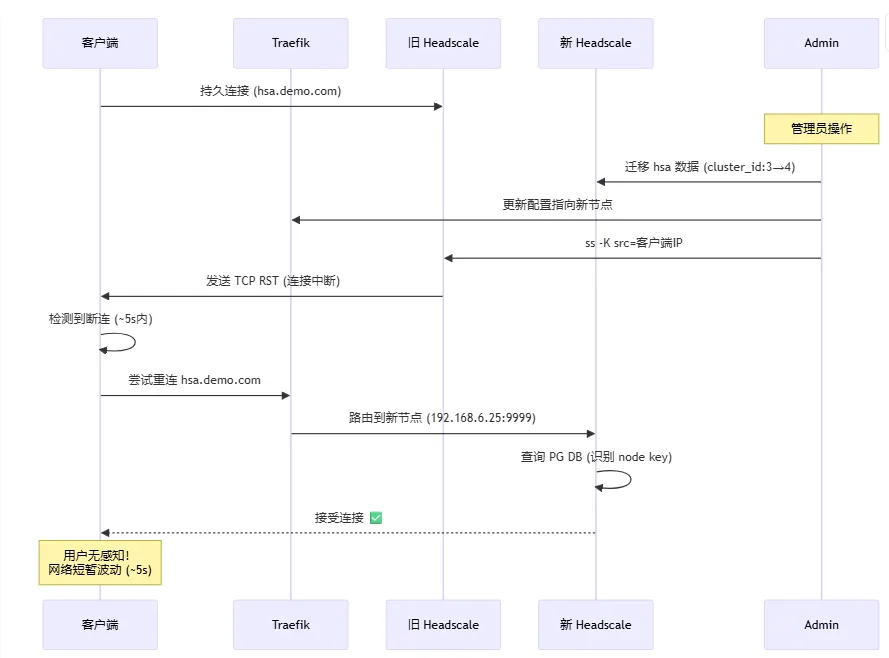
实战迁移步骤
1) 迁移用户数据
# 从旧节点导出用户相关数据
pg_dump -h node3-db -U headscale -t nodes -t ip_addresses \
--where="user_id = (SELECT id FROM users WHERE name = 'hsa')" \
> hsa_data.sql
# 修改 cluster_id 并导入新节点
sed -i 's/cluster_id: 3/cluster_id: 4/g' hsa_data.sql
psql -h node4-db -U headscale -d headscale < hsa_data.sql
2) 热更新 Traefik 路由
http:
routers:
hsa-router:
rule: "Host(`hsa.demo.com`)"
service: "headscale-cluster4"
entryPoints: ["https"]
curl -X POST http://traefik/api/providers/file?dynamic=true
3) 在旧节点精准中断目标连接
ss -K "dport = 7890 and src 203.0.113.5"
客户端通常会在数秒内自动重连到新节点,继续沿用 node key,不需要重新认证。
迁移效果(原文实测)
- 迁移总时长:通常小于 15 秒
- 客户端中断:通常 1-5 秒
- 重新认证率:接近 0%
本文已同步到 Larktun 博客,原始内容与更新请以原文为准: headscale-系列:Headscale-SaaS-环境下的用户无缝切换实战