Headscale Cluster for Large-Scale Device Onboarding
· 3 min read
This post explains how to evolve headscale from a monolith into a near linearly scalable cluster using cluster_id sharding, shared PostgreSQL, an admission/control service (ACS), strict query isolation, and incremental netmap rebuilds.
Original post: headscale 系列:组建 headscale 集群,把设备接入能力做成“无限接近无限”
Core Takeaway
These building blocks move headscale toward a SaaS-style control plane:
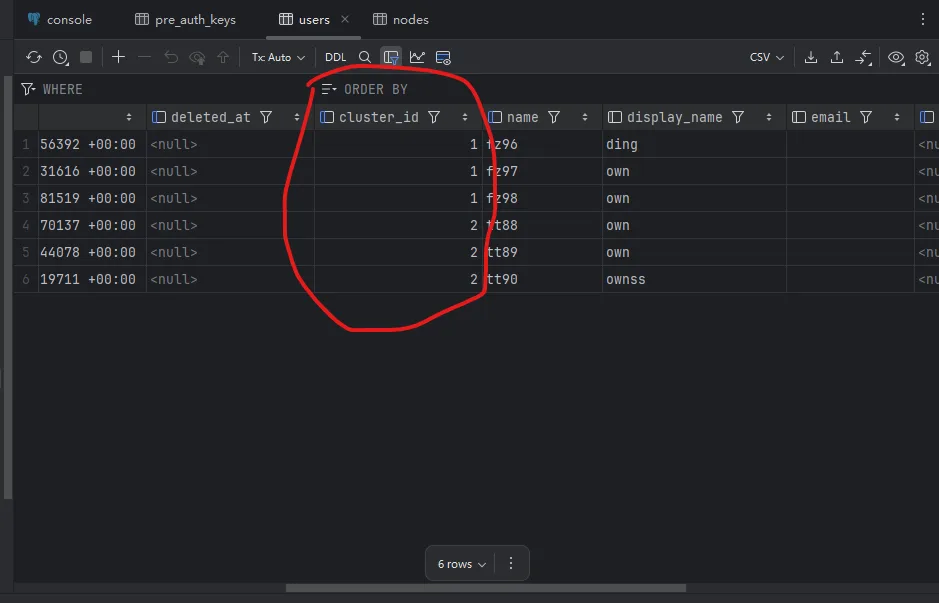
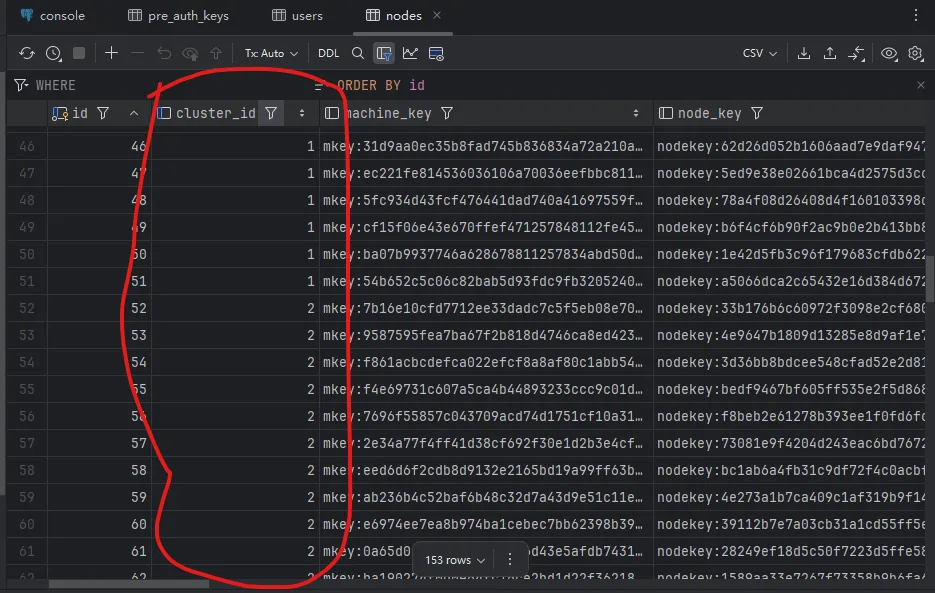
cluster_idlogical sharding- Shared PG/PG cluster
- ACS for tenant assignment and sticky routing
- Mandatory
cluster_idfiltering in DAO/ORM - Incremental netmap calculation instead of full rebuilds
Architecture Highlights
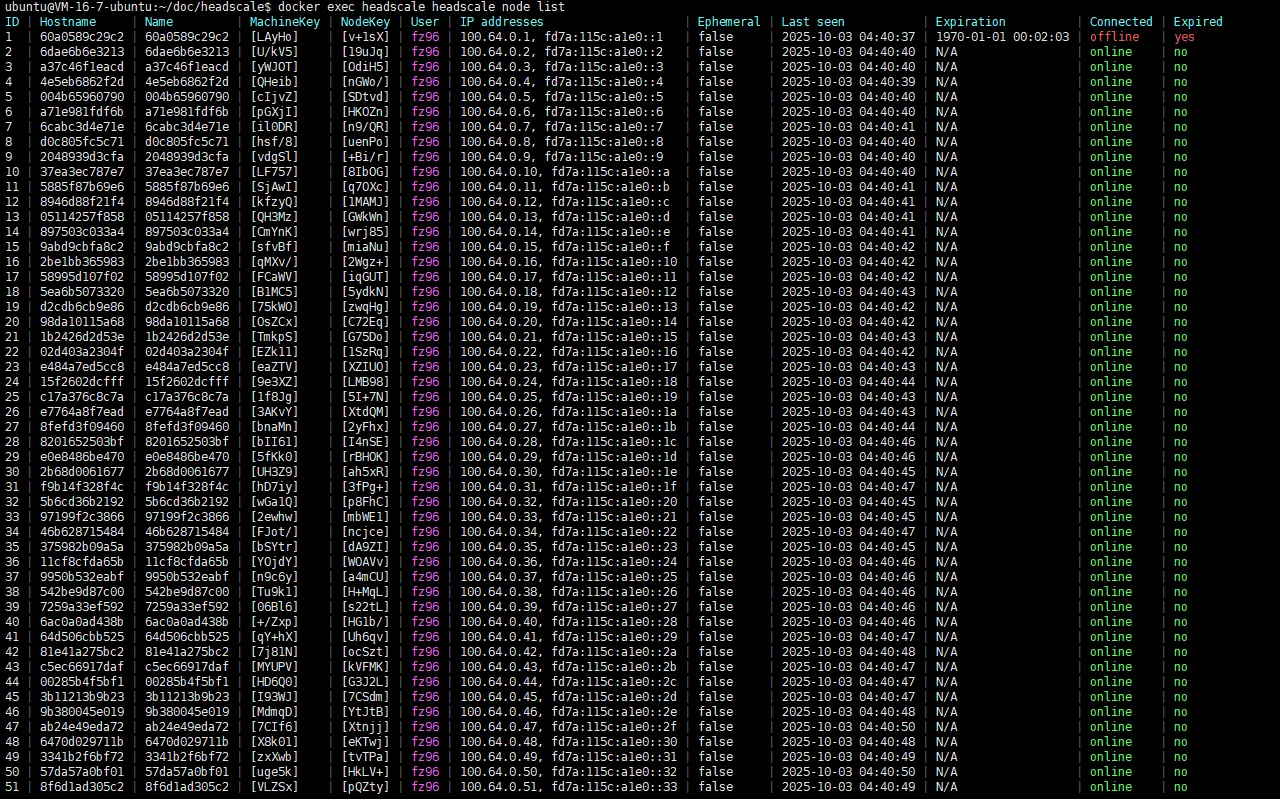
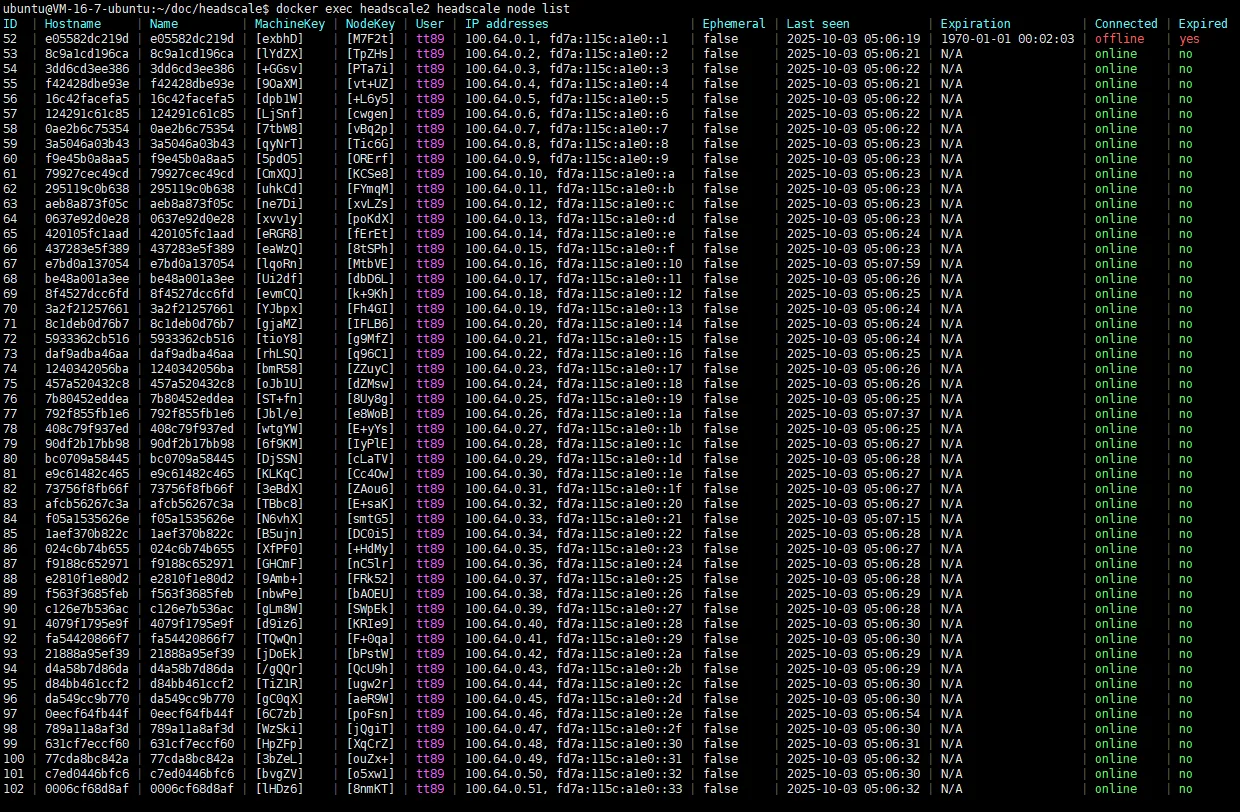
- Multiple
headscalenodes run in parallel, each bound to a uniquecluster_id. - All nodes share one database layer, but every query must include
cluster_id. - ACS handles first-time assignment, policy constraints, and balancing.
- LISTEN/NOTIFY + debounce limits netmap recomputation scope and CPU impact.
Startup Example
CLUSTER_ID=A \
PG_DSN="postgres://..." \
DERP_MAP_URL="https://derp.example.com/map.json" \
./headscale --config ./config.yaml
Isolation Snippets
ALTER TABLE nodes ADD COLUMN cluster_id TEXT NOT NULL DEFAULT 'default';
CREATE INDEX idx_nodes_cluster_id ON nodes(cluster_id);
func (c *ClusterDB) Scoped() *gorm.DB {
return c.db.Where("cluster_id = ?", c.clusterID)
}
Incremental Netmap Strategy
- On data changes, emit
NOTIFY netmap_dirty(cluster_id, scope_key). - Each node consumes only matching
cluster_idevents. - Rebuild only affected scope (
user/tag/route domain) rather than full sets. - Add caching + versioning to minimize redundant computation.
Demo Screenshots
Related Link
- Project: OwnDing/headscale-saas
This article is mirrored on the Larktun blog. For source updates and original context, refer to: headscale 系列:组建 headscale 集群,把设备接入能力做成“无限接近无限”